Tensorflow是一个强大的深度学习框架,通过它可以方便地配置、训练以及评估模型。本次学习材料主要是Tensorflow官方教程、Deeplearning.ai课程以及一些网上的资料,并会加上自己的一些理解及想法。此外,本次学习针对的是机器学习在Tensorflow中的应用,不会对其理论做过多的阐述。
理解Tensorflow
Tensorflow这个词由Tensor与Flow组成。Tensor为张量,不用管维基百科上多么复杂的解释,在这里张量就相当于一个容器,数据的容器。它可以是一维、二维、三维乃至n维的向量,也可以是文字、图像或者视频。任何想要在框架中使用的数据都需要定义成Tensorflow的张量,之后框架才能对它们进行操作。
而flow为流动。以CNN模型为例,我们将图像看作一个n×n×3的矩阵,输入模型,通过前向传播,最终得出它的损失值。每一次运算就相当于一个节点(node),前向传播就好像数据流过各个节点的过程,而数据最终以损失值的形式输出。
Tensorflow的框架思想就是如此,在使用时有下列几个步骤:
1. 创建张量(Tensor)
2. 写出张量的运算过程,构成一个计算网络(computational graph)
3. 初始化张量
4. 创建Session
5. 运行Session
Tensorflow的计算依赖于一个高效的C++后台,而Session的作用就是Tensorflow与后台的连接,可以把目标事物通过Session传递到后台,再运行就可以进行计算了,这个之后会通过例子说明。从这些步骤可以看出,我们只需将前向传播的张量和网络设置好,其他事情,像什么反向传播,参数更新啥的就全都可以交给Tensorflow做了。
Tensorflow中的数据
Tensorflow的数据储存在张量之中,并且它们有三种形式:constant、placeholder和variable
constant
constant为常量,它的值在整个运算过程中不会变化,若我们不想在训练中改变某些参数的值,就可将它们设置为constant。比如在Neural Style Transfer中,我们希望训练时保持模型不变而只改变输入图像,就需要将模型设置为常量。
在Tensorflow中设置常量要使用constant函数(官方文档),我们会发现官方文档中constant函数的参数有很多,但一般情况下我们只需要使用它最基本的几个参数就够了:1
2import tensorflow as tf #导入类
const = tf.constant(3.0, dtype = tf.float32) #创建constant
程序第一行用import将tensorflow类导入程序中,以便调用。这是所有Tensorflow程序都拥有的语句。第二行使用constant函数将3.0赋值给const,并设置数据类型为float32。
若用print函数直接将const输出,得到的结果为:1
Tensor("Const:0", shape=(), dtype=float32)
它并非我们想的那样输出const的值,因为const此时是框架中的一个张量,无法用print直接输出。若要输出const的实际值,则需要创建一个Session,将const带入并运行,最后关闭Session:1
2
3sess = tf.Session() #创建一个Session
print(sess.run(const)) #sess.run(const)得到const运行后的值,再通过print输出
sess.close()
run是Session的一个method,通过它可以运行computational graph并输出目标事物的值。运行后得到输出为:1
3.0
placeholder
placeholder有点像函数中的形参,它的作用是在computational graph中为数据预留一个位置,在每次运行Session时再给它赋值。因此它常常用于分批训练,每次运行Session时带入一个batch的训练集。由于不用赋值,因此定义placeholder只需要指定数据类型(官方文档):1
2import tensorflow as tf
a = tf.placeholder(tf.int32) #创建placeholder
当运行Session时,需要在run函数中对placeholder进行赋值,赋值方法为增加参数feed_dict = {placeholder1: value1, placeholder2: value2 …}:1
2
3sess = tf.Session()
print(sess.run(a, feed_dict = {a: [3, 4]})) #用feed_dict带入数值
sess.close()
得到输出为:1
[3 4]
variable
variable是Tensorflow中的变量,可以随Session运行而改变,因此在训练模型中常用于模型训练参数(W、b等)的定义。Variable在定义时需要指定初始值,并且在运行Session前需要使用initializer进行初始化(官方文档):1
2
3
4
5
6
7import tensorflow as tf
W = tf.Variable(3.0, dtype = tf.float32) #创建variable
init = tf.global_variables_initializer() #创建一个全局变量的initializer
sess = tf.Session()
sess.run(init) #运行initializer,使得变量初始化
print(sess.run(W))
sess.close()
这里需要注意的是创建variable时的函数首字母是大写的,而constant和placeholder的函数都是小写的,很容易就搞错了(吐糟一句:统一一下函数命名这么难吗-_-||)。这里的initializer用的是global_variables_initializer(),用Session运行它可以初始化所有全局变量。程序运行结果为:1
3.0
我们还可以使用assign给变量重新分配一个值,当然也需要通过Session来实现:1
2
3
4fixW = tf.assign(W, 2.0) #将2.0分配给W
sess.run(fixW)
print(sess.run(W))
sess.close()
得到输出为:1
2.0
构建computational graph
创建张量后的第二步就是构建一个computational graph,我们可以通过Tensorflow中的各种运算建立节点以形成网络。常用的运算符有:tf.add、tf.subtract、tf.multiply、tf.divide、tf.square等。
以线性模型为例。设:
则它的损失值可通过如下函数求出:
由于W、b是我们要训练的参数,而x、y为模型的输入,因此设W、b为variable,x、y为placeholder。通过张量间的各种运算求出loss并输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import tensorflow as tf
#创建Tensor
W = tf.Variable(0.3, dtype = tf.float32)
b = tf.Variable(-0.3, dtype = tf.float32)
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
#构建computational graph
linear_model = tf.add(tf.multiply(W, x), b) #linear_model = Wx + b
loss = tf.square(tf.subtract(y, linear_model)) #loss = (y - linear_model) ^ 2
loss = tf.reduce_sum(loss) #求和
#初始化
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
#输出
print(sess.run(loss, feed_dict = {x: [1, 2, 3, 4], y: [0, -1, -2, -3]}))
#关闭Session
sess.close()
输出结果为:1
23.66
而实际上Tensorflow已经将最常用的算数运算符重载了,因此在运算时也可以直接使用,其结果是一样的:1
2
3
4
5#构建computational graph
linear_model = W * x + b #linear_model = Wx + b
loss = (y - linear_model)**2 #loss = (y - linear_model) ^ 2
loss = tf.reduce_sum(loss) #求和
sess.close()
其构建的computational graph为: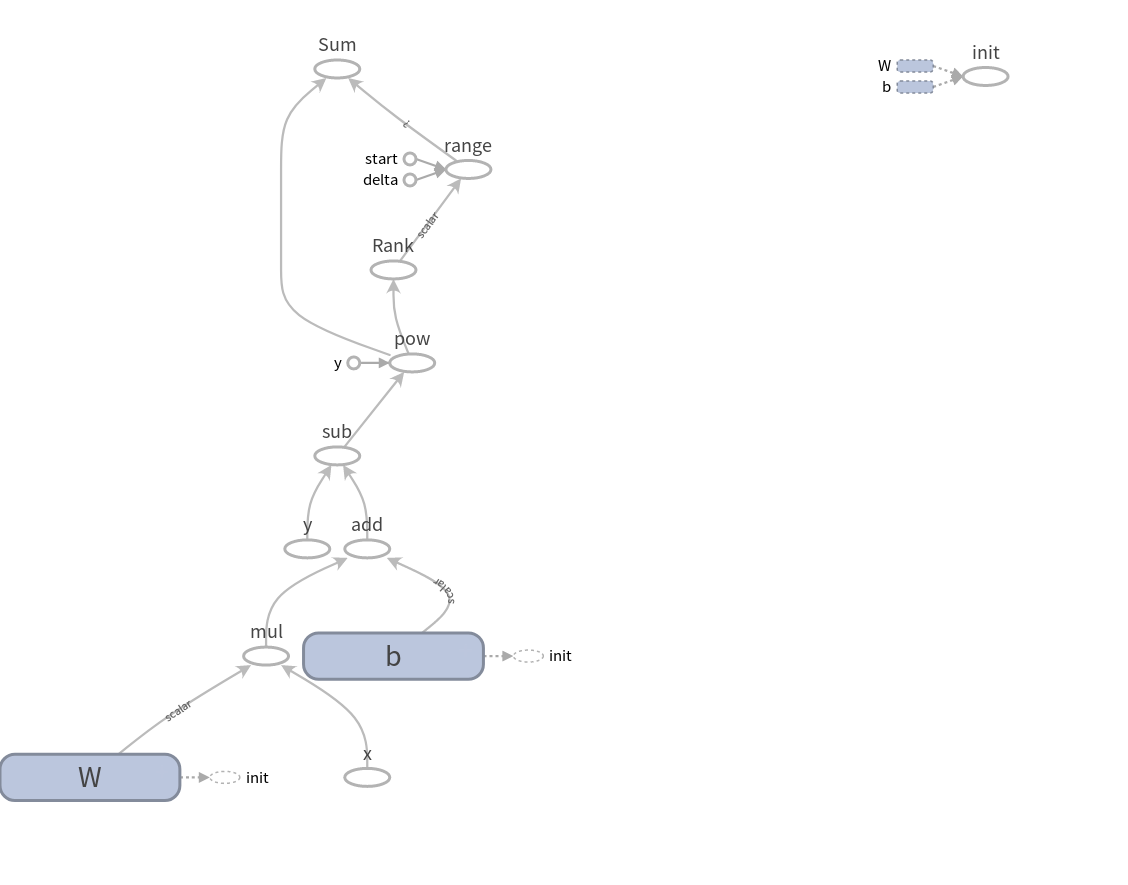
可以看到张量通过各个运算节点流过整张computational graph,并最终形成了输出。
这张图是通过Tensorflow内置的Tensorboard自动生成的。图中各张量的名称是在定义它们时加上参数name得到的。若想使用Tensorboard可视化整个训练过程,只需将输出改为:1
2
3
4#输出
writer = tf.summary.FileWriter("output", sess.graph)
print(sess.run(loss, feed_dict = {x: [1, 2, 3, 4], y: [0, -1, -2, -3]}))
writer.close()
运行后便会在代码所在目录新建一个名为output的文件夹。再打开一个终端中输入如下代码:1
tensorboard --logdir=path/to/output #output文件夹所在位置
回车后便会自动生成一个Tensorboard界面,还是很方便的。
使用optimizer训练参数
Tensorflow最核心的功能便是训练参数了,在构建好computational graph之后,我们可以使用它内置的各种优化方式(optimizer)来方便快捷地实现参数训练。
接之前线性模型的例子,我们希望通过训练,改变W和b的值,使得loss减小,即模型输入x所得到的linear_model值越来越接近y。Tensorflow提供了很多优化方法,这里选择最简单的梯度下降法(gradient descent)。我们只需设置优化方法(optimizer)及优化目标,Tensorflow便会自动计算梯度并且更新参数。其实现代码如下:1
2
3
4
5
6
7
8
9#接之前代码
#设置优化方式
optimizer = tf.train.GradientDescentOptimizer(0.01) #设置优化方式为梯度下降,学习率为0.01
train = optimizer.minimize(loss) #设置优化目标为降低loss
for i in range(1000): #迭代1000次
sess.run(train, feed_dict = {x: [1, 2, 3, 4], y: [0, -1, -2, -3]})
print(sess.run([W, b, loss], feed_dict = {x: [1, 2, 3, 4], y: [0, -1, -2, -3]}))
sess.close()
我们对模型迭代了1000次,每次迭代时,W与b的值都会更新,使loss减小。最终得到结果为:1
[-0.9999969, 0.99999082, 5.6999738e-11]
可以看到,经过1000次迭代后,损失值已经非常小了。至此我们已经成功的使用Tensorflow训练了一个线性模型!
小结
- Tensorflow有constant、placeholder、variable三种数据形式。其中需要训练的参数设为variable,训练集设为placeholder,常量设为constant。
- 通过运算建立张量流动的节点,构成computational graph,形成前向传播通道
- 设置optimizer与优化目标来训练模型。