训练数据对于机器学习来说是必不可少的,因此在每个机器学习任务之前都会有一个搜集数据的过程,这个搜集过程通常来说是枯燥且费时的。不像很多公司本身就是数据的生产者,对于我们普通学习者来说,能使用的大部分数据均来自于网络。我们可以从网页上手动获取所需的数据,复制粘贴到本地,然而这是相当麻烦的。通过python我们可以模拟浏览器对网页进行抓取,并自动筛选出所需要的数据,大大提高搜集数据的效率。本次学习材料主要是Python for Everyone课程、BeautifulSoup官网以及一些网上的资料。
socket接收数据
计算机上的应用程序通常是通过套接字(socket)与外界进行联系的。socket就相当于一个端口,程序通过它向网络服务器发出请求或应答网络请求。Python拥有一个内置的socket库,在它的帮助下我们能够轻松连接网络服务器并获取服务器上的数据。在使用之前我们需要导入socket库:1
import socket
使用socket函数为我们的程序定义一个socket:1
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #定义一个socket,并命名为mysock
第一个参数socket.AF_INET代表这个socket是用于服务器与服务器之间的网络通信;第二个参数socket.SOCK_STREAM代表它是基于TCP的流式socket通信。我们在网页抓取中使用的都是基于TCP的网络通信,因此在使用socket获取网络数据时,这些参数都是不变的。
定义完socket后,我们需要将它连接到网络上的服务器端口。通常服务器不同端口分别提供不同的服务,TCP/IP协议规定Web服务使用80号端口,因此我们使用connect将socket连接到指定服务器的80号端口。这里我们以data.pr4e.org为例:1
mysock.connect(('data.pr4e.org', 80)) #连接到data.pr4e.org的80号端口
若想获得该服务器上的某个文件(如romeo.txt),我们就需要通过socket对服务器发出请求。根据HTTP协议,请求数据时需要使用send向服务器发送一个结尾为空行的GET指令。由于python3使用Unicode来表示文字,而在网络传输中使用的是二进制格式,因此我们需要使用encode函数将Unicode编码为二进制再通过socket传递;同样在接收服务器数据后我们也需要使用decode对数据进行转换。代码如下:1
2cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\r\n\r\n'.encode() #设置GET指令并编码
mysock.send(cmd) #通过socket发送指令
发送完指令后就可以等待接收服务器的数据了。在这里我们使用一个for循环对数据进行接收,每次接收512个字节,直到接收完毕。代码如下:1
2
3
4
5while True:
data = mysock.recv(512) #每次接收512字节
if(len(data) < 1): #若接收数据为空,则跳出循环
break
print(data.decode(),end='') #编码后打印接收到的数据
最后接收完毕,我们需要将socket关闭:1
mysock.close()
程序输出结果为:1
2
3
4
5
6
7
8
9
10
11
12
13
14HTTP/1.1 200 OK
Date: Sun, 14 Mar 2010 23:52:41 GMT
Server: Apache
Last-Modified: Tue, 29 Dec 2009 01:31:22 GMT
ETag: "143c1b33-a7-4b395bea"
Accept-Ranges: bytes
Content-Length: 167
Connection: close
Content-Type: text/plain
But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with grief
接收到的数据分为两个部分,它们使用一个空行分隔。空行前的部分是文件的头部(headers),它由网络服务器生成,用来描述文件的属性。比如最后一项Content-Type: text/plain表示文件是一个纯文本。空行后的部分才是文件真正的数据部分,因此在接收完数据后我们还需要对数据进行部分处理才能使用。在这里我们接收的是文本文件,而其他数据类型如图片等都是类似的,因为它们在网络中都是通过二进制传递。我们只需在接收完成后进行相应的解码就可以了。
使用socket库需要我们手动发送请求给服务器并接收,还是有些麻烦的。接下来我们将使用另一个更加方便的库来实现之前的功能。
urllib接收数据
urllib也是python的一个内置库,利用它我们可以把接收到的数据当作一个file进行处理,非常的方便。在使用之前我们需要导入urllib库:1
import urllib.request, urllib.parse, urllib.error
在这里我们只需要一个命令便可以请求并接收所需文件数据。:1
fhand = urllib.request.urlopen('http://data.pr4e.org/romeo.txt')
fhand是网络文件的句柄(handle),我们可以像file那样对fhand进行操作,比如使用for循环将文件内容逐行显示:1
2for line in fhand:
print(line.decode().strip()) #打印解码后的行
也可以使用read()直接将整个文件读取为一个string。这里要注意,使用read()时文件不能大过计算机的内存:1
print(fhand.read()) #读取整个文件并打印
与socket不同,urllib会将接收数据的头部(headers)与内容(content)分开,因此上面程序运行输出的是不含头部的文件数据。若要获取文件的头部,我们只需对fhand使用info()即可;1
info = fhand.info()
BeautifulSoup分析网页源码
通常在服务器抓取数据时,我们不知道目标文件的网络地址,因此需要通过分析网页的源码来得到它们。例如我们想获取下图百度首页上的logo图片:
但我们只知道百度的网址是:www.baidu.com。这时候我们只能通过python抓取网页的源码,对其进行分析后才能得到该图片的网络地址。分析源码后我们得到表示该图片的img标签:1
<img hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" usemap="#mp" width="270" height="129">
其中src属性的值就是该图片的网络地址。由于网页的源码通常非常复杂,并且很多网站编写时并不是特别规范,因此使用传统方式对源码进行分析是非常困难的。幸好我们有个强大的工具——BeautifulSoup(不知道哪位老哥起的奇葩名字)。它可以将HTML的标签通过节点表示,建立一个文档树。通过这个文档树,我们可以方便地找到想要的标签并提取出其中的内容。在整个数据抓取过程中,我们利用urllib抓取网页源码,再使用BeatifulSoup对网页源码进行分析。不过在这之前我们需要对HTML的语法结构以及标签类型有一个初步的认识,具体可以参考MDN的教程。
根据官网提示安装BeautifulSoup,安装完毕后便可以开始写程序了。我们以一个简单的网页(www.dr-chuck.com/page1.htm)为例,它的HTML代码为:1
2
3
4
5
6
7
8
9
10
11<html>
<head></head>
<body>
<h1>The First Page</h1>
<p>
If you like, you can switch to the
<a href="http://www.dr-chuck.com/page2.htm">Second Page</a>
.
</p>
</body>
</html>
首先导入urllib与BeautifulSoup库:1
2import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
使用urllib读取页面源码,并储存在一个变量中:1
2url = "http://www.dr-chuck.com/page1.htm" #设置网页链接
html = urllib.request.urlopen(url).read() #将网页源码储存在变量html中
使用该变量创建一个BeautifulSoup对象:1
soup = BeautifulSoup(html, 'html.parser') #创建BeautifulSoup对象
其中第二个参数‘html.parser’表明BeautifulSoup使用的解析器为Python标准库中的HTML解析器,除此之外它还支持一些第三方解析器如lxml。lxml解析器速度更快且更加强大,不过需要安装之后才能使用。对于我们这种小打小闹,python标准库的解析器已经足够啦。
利用BeauifulSoup我们可以快速获得源码的标签(Tag)。比如我们需要获得源码中的a标签,则可使用如下代码:1
print(soup.a)
其输出为:1
<a href="http://www.dr-chuck.com/page2.htm">Second Page</a>
但是通过这种方式我们只能获得源码中的第一个a标签。若我们希望查找所有标签,可使用find_all函数,其完整定义为:find_all(name, attrs, recursive, text, **kwargs)。它有很多参数,但最常用的是name(标签类型)和attrs(标签属性)。我们可以通过指定标签类型或属性来筛选出满足条件的所有标签,并将它们合并为一个列表(list)。使用举例如下:1
2
3print(soup.find_all('a')) #检索所有a标签
print(soup.find_all(href="http://www.dr-chuck.com/page2.htm")) #检索所有属性满足的标签
print(soup.find_all('a', href="http://www.dr-chuck.com/page2.htm")) #检索所有属性满足的a标签
由于网页源码中只有一个a标签,因此它们输出相同,均为:1
[<a href="http://www.dr-chuck.com/page2.htm">Second Page</a>]
由于输出的是一个列表,因此我们能够通过for循环来对列表中每一个标签进行操作。数据抓取中最常用的操作是获取标签的属性,我们可以通过以下两种方式得到:1
2print(soup.a['href'])
print(soup.a.get('href'))
它们的作用是一样的,输出得到a标签的’href’属性值:1
2http://www.dr-chuck.com/page2.htm
http://www.dr-chuck.com/page2.htm
爬虫抓取数据实例
在这里我们将利用之前介绍的相关知识,使用爬虫从一个动漫网站上抓取动漫图片。在写代码之前我们需要观察网站及其源码,找到一些关键链接以及标签来方便之后的操作。网站外观大致如下:
我们发现网站的图片分布在各个页面上,而每个页面的网址是有规律的,它可以表示为如下形式:1
http://konachan.net/post?page= + 页码数 + &tags=
在每个页面上我们需要点击缩略图来跳转到包含相应原图的网页上,因此我们要找到每个缩略图所指向的地址。使用火狐浏览器-选项-Web开发者-查看器,我们能够轻松得到页面任意位置所对应的网页源码: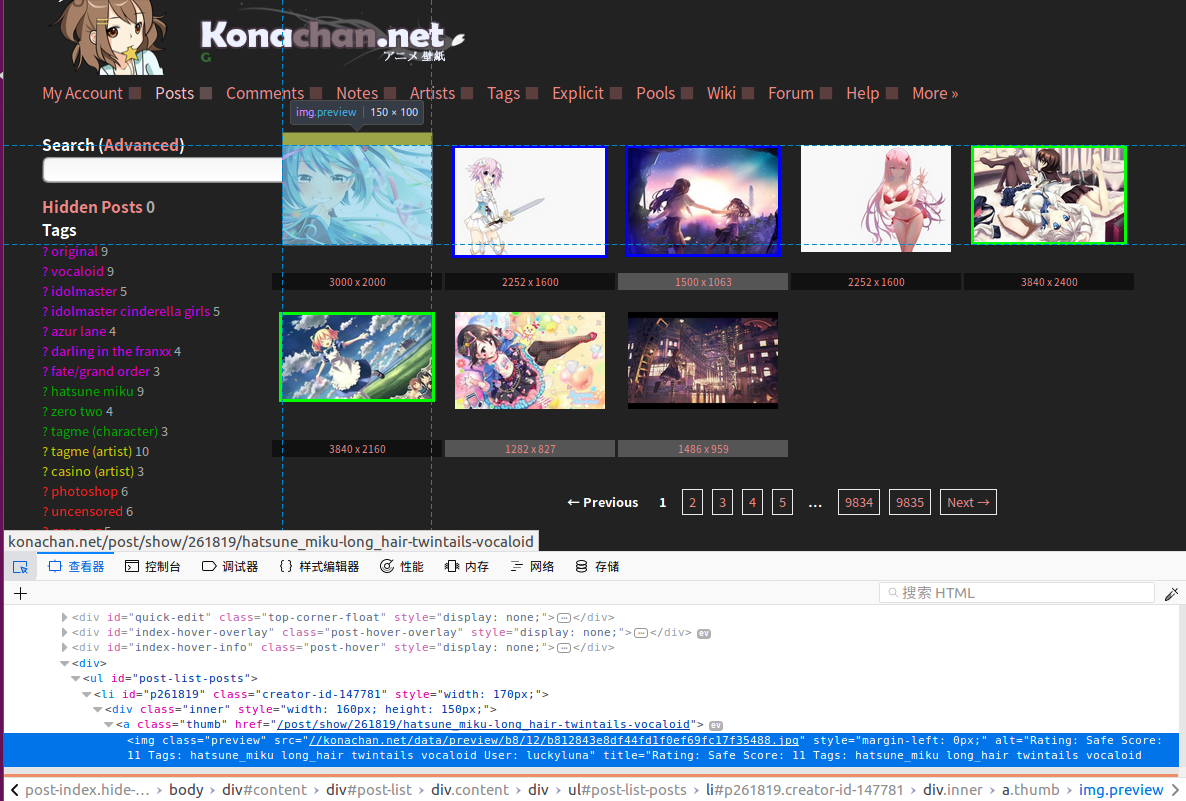
通过查看器我们发现每个缩略图对应的超链接标签(即a标签)都有一个类属性(class)为’thumb’。同样在包含原图的网页源码中,我们发现每一张原图对应的图片标签(即img标签)都有一个类属性为’image’。至此我们就获得了写代码需要的所有信息,可以开始写代码了。首先还是导入所需的库:1
2import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
我们使用一个循环来获得不同页面的网址,并通过urllib获取页面的源码。这里我们选择抓取前100页的图片:1
2
3
4surl= "http://konachan.net/post?page="
for i in range(1,101):
url = surl + str(i) + "&tags=" #得到第i页网址
html = urllib.request.urlopen(url).read() #得到第i页源码
创建BeautifulSoup对象,并通过find_all函数找到所有类属性为‘thumb’的超链接标签:1
2soup = BeautifulSoup(html, 'html.parser') #创建BeautifulSoup对象
tags = soup.find_all('a', class_="thumb") #得到所有类属性为thumb的的超链接标签(由于class为python关键字,因此使用class_来表示)
使用for循环遍历标签列表,得到每一个标签的链接地址:1
2for a in tags:
iurl = 'http://konachan.net' + a['href']; #得到网络地址
这些网络地址均为包含原图的网页。使用与之前相同的方法得到网页源码,并利用BeautifulSoup得到图片地址:1
2
3
4ihtml = urllib.request.urlopen(iurl).read() #得到网页源码
isoup = BeautifulSoup(ihtml, 'html.parser') #创建BeautifulSoup对象
itag = isoup.find_all('img', class_='image') #得到所有类属性为image的img标签
iiurl = 'http:' + itag[0]['src'] #得到图片地址
最后使用urllib获得图片数据,并保存至本地。由于我们不确定图片的格式,因此使用图片地址末尾的后缀来创建文件:1
2
3f = open('image_name' + '.' + iiurl.split('.')[-1], 'wb') #创建图片文件
f.write(urllib.request.urlopen(iiurl).read()) #写入图片数据
f.close #关闭图片文件
完整代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
k = 1;
surl= "http://konachan.net/post?page="
for i in range(1,101):
url = surl + str(i) + "&tags="
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all('a', class_="thumb")
for a in tags:
iurl = 'http://konachan.net' + a['href'];
ihtml = urllib.request.urlopen(iurl).read()
isoup = BeautifulSoup(ihtml, 'html.parser')
itag = isoup.find_all('img', class_='image')
iiurl = 'http:' + itag[0]['src']
f = open('images/' + str(k) + '.' + iiurl.split('.')[-1], 'wb')
f.write(urllib.request.urlopen(iiurl).read())
f.close
print('image' + str(k) + ' produced')
k = k + 1
在这里我们用递增的变量k来命名文件,以方便之后的操作,并将它们保存在images文件夹中。至此我们便使用爬虫完成了一个简单的数据抓取任务。当然在抓取数据时还会遇到各种其他问题,比如需要登录才能获取数据,或者数据被加密了(这在视频网站很常见),之后有时间再研究吧。最终抓取的图片如下: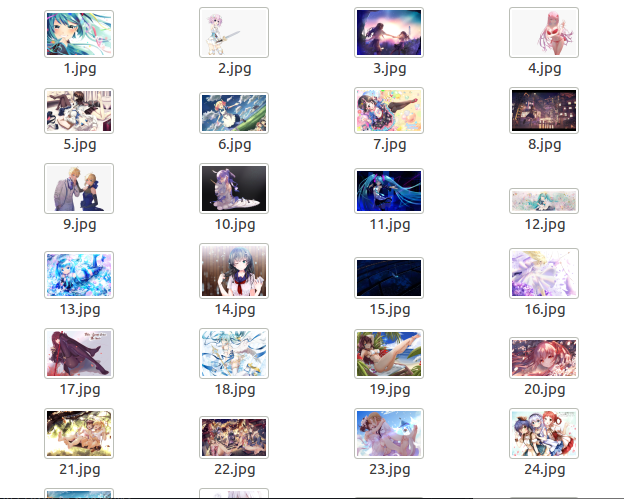
小结
- 使用socket能够连接网络服务器并进行数据请求及回应。
- 使用urllib能够更方便地实现网页抓取。
- BeautifulSoup能够帮助我们分析网页源码并获取有用信息。