作为一个苦逼的学生党,如果没有实验室或者公司支持,自己实践深度学习时经常会遇到一些困难:“自己网上搜集数据好麻烦,现成的数据集很多又都是要申请才能获得”;“破笔记本也太烂了,训练个两层CNN就要跑好几天,要达到满意的效果不知道要跑到猴年马月了”。在没有能力或者单纯不想从零开始训练模型时,迁移学习无疑是一大神器。我们可以从网上下载别人已经训练好的模型,将它们迁移到我们自己的任务中来。这些模型可能已经用了大量数据训练了很长时间了,因此使用它们可以大大提高我们的效率,并且能得到非常好的效果。本次学习材料主要是Deeplearning.ai课程以及当年本人毕设论文的部分内容,使用的是基于Matlab的Matcaffe框架,初步实现了人脸识别应用的One-shot learning。献丑了献丑了。
概念
迁移学习(Transfer Learning)顾名思义就是把已经训练好的模型迁移到新的任务中来使用。这里有一个前提就是新的任务和原来模型的目标任务有一定的相关性。比方说旧的模型是用来识别人脸的,就不能把它迁移去识别汽车,但可以用它来识别表情。但是这种所谓相关性是非常主观的,目前应该并没有一个严谨的理论来描述这种相关性,更多的是凭借直觉或者经验判断两者是否拥有一些共同特征。
通常根据我们拥有的训练数据多少以及新旧任务的相关性程度,可以对训练好的模型进行不同的操作。如果只有少量的训练数据并且新旧任务相关性较大的情况下,我们可以把训练好的模型当作一个特征提取器,通过它来提取数据特征,再进行进一步的训练。以CNN模型为例:
这是CNN的典型结构。输入图像$x$,经过一系列层最终得到输出$\hat{y}$,它代表了输入$x$属于各分类的概率。通常CNN最后一层为softmax层,我们可以将它删除,并根据自己的分类数量添加一个自定义softmax层。在使用数据训练时,我们将原模型的权重冻结,只训练我们自己定义的那层即可,这在很多深度学习框架中都能够实现。这种方式就相当于把数据通过模型提取出一系列特征,再将这些特征输入到我们定义的softmax层中用于分类。当然我们不止可以定义一层,也可以在原模型的基础上增加若干层。
如果我们有大量训练数据或者新旧任务相关性不是特别大的时候,可以只将(删除softmax层后)原模型的一部分层冻结,用训练数据训练剩余的层。或者干脆就将原模型权重作为现模型的初始值,训练整个模型。这些方式需要的训练数据量以及训练迭代次数依次增加。
应用实践
在这里使用迁移学习实现一个可交互的人脸识别应用,大致过程为:输入图像->检测图像中的人脸->剪裁人脸并缩放成标准大小->输入模型进行识别->若识别身份有误或者身份未在数据文件中,则人工修改身份->训练模型。其中人脸检测模型使用的是深圳先进技术研究所的MTCNN模型,人脸识别模型使用的是牛津大学的Visual Geometry Group的VGG-Face。由于条件有限,训练时仅训练自定义的softmax层。
模型简介
MTCNN
MTCNN由三个串联的CNN网络组成,它能够检测输入图片中的人脸,并将其眼睛、鼻子与嘴唇的几个关键位置找到并标记。其示意图如下: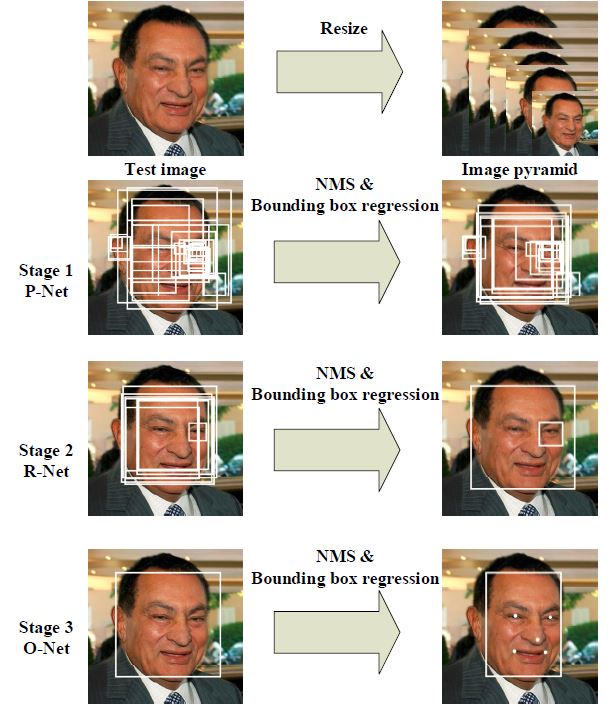
识别的步骤为:先将图片进行缩放,构造一个图像金字塔,再将它们输入到一个三级串联的网络中(P-Net,R-Net,O-Net),其中: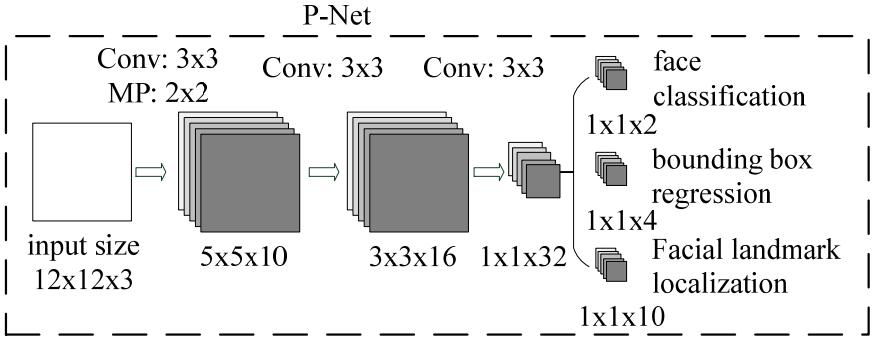
Proposal Network(P-Net):该网络结构主要用来得到人脸区域的候选窗口和边界框的回归向量。再使用边界框的回归向量,对候选窗口进行校准,最后通过非极大值抑制(NMS:non-maximum suppression)来合并高度重叠的候选框。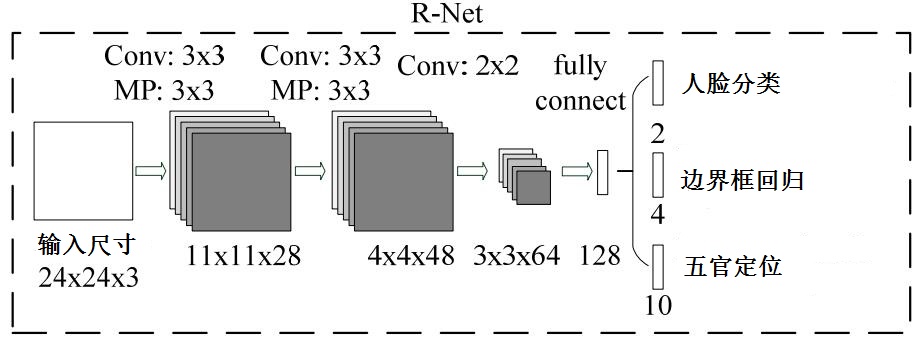
Refine Network (R-Net):结构与 P-Net 类似,亦是通过边界框回归和NMS,在P-Net中输入的候选框来去掉一些不正确的候选框,从而获得更精确的选取边框。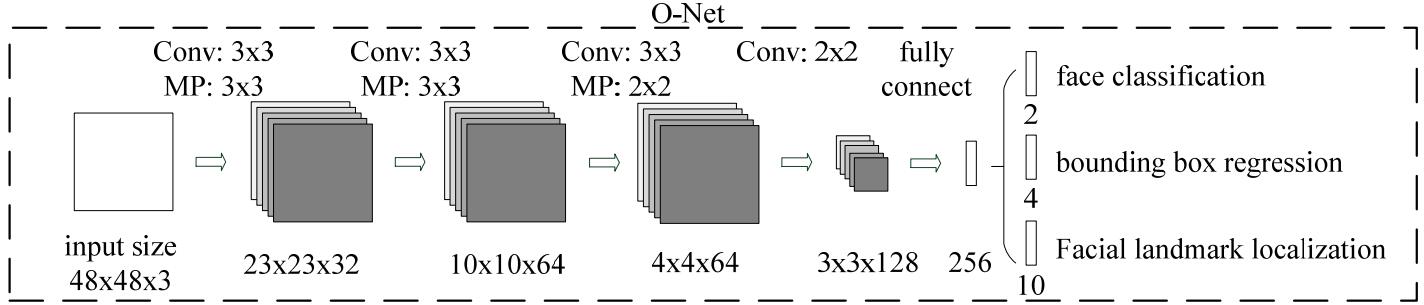
Output Network(O-Net):该层比R-Net层又多了一层卷积层,所以处理的结果会更加精细。其作用和R-Net一致,但是它对人脸区域进行了更多的监督,同时还会输出5个特征点。
VGG-Face
VGG-Face是一个通过260万张图片训练出来的CNN模型,具有很深的结构。它由1个输入层,13个卷积层,5个pooling层,2个全连接层和1个softmax层组成。其网络结构如下图所示: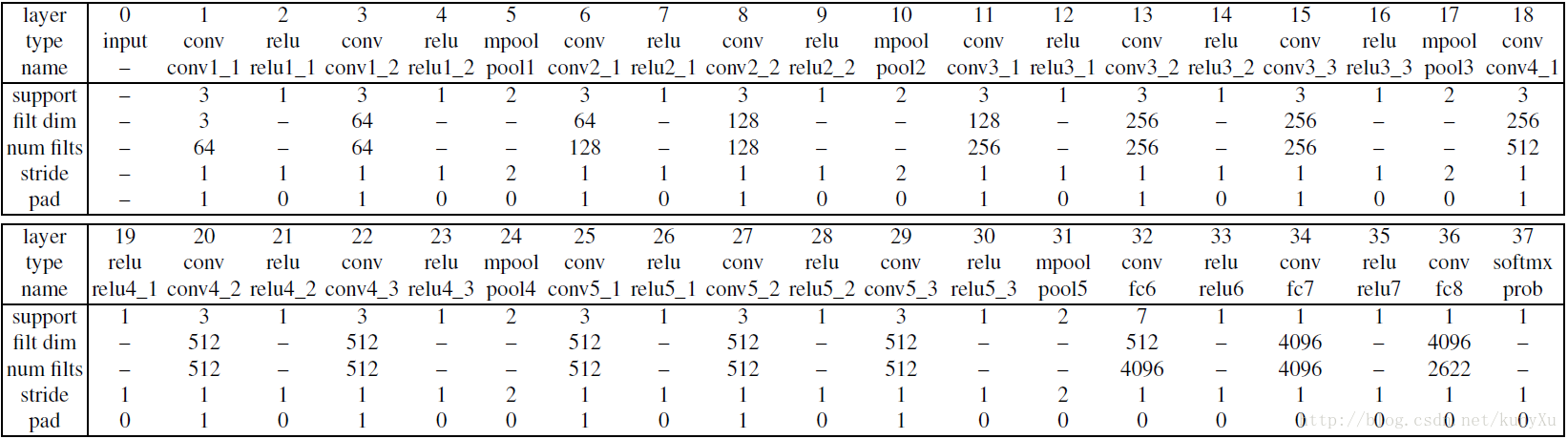
整个网络非常深,并且它仅用了比别人少得多的数据,却取得了更好的效果,在LFW(Labeled Faces In the Wild)与YFW(YouTube Faces Dataset)中均取得了当时世界顶级的成绩。
代码实现
应用实现时使用了Matlab的APP Designer交互界面,因此部分代码会包含App Designer的部分函数,但这不是本文的重点。
Caffe的模型包含模型数据和模型框架两个文件,它们的后缀分别为caffemodel和prototxt。若要修改一个模型的网络结构,我们仅需在框架文件中修改层的定义即可。通常层的定义形式如下:1
2
3
4
5
6
7
8
9
10
11layers {
bottom: "data" %输入为data
top: "conv1" %输出为conv1
name: "conv1" %层名字为conv1
type: CONVOLUTION %层类型为卷积层
convolution_param { %层参数定义
num_output: 64 %filter数量为64
pad: 1 %步长为1
kernel_size: 3 %filter大小为3
}
}
在迁移学习中,我们要把VGG-Face的最后一层softmax去除,因此只需在VGG-Face框架文件中将最后一层的定义删除即可。在VGG-Face之后我们要加一层softmax层来预测自己的图像,由于本次应用中会有人员增加,softmax层的长度也会随之增加,因此在这里没有使用框架定义softmax层,而是直接在matlab中实现。并且通过自定义的数据格式,将每个人员的名字,特征以及对应softmax层的权重储存在一个cell数组中,并保存在名为face_data.mat文件中。cell数组结构示意如下:
从左至右依次为第$i$个身份对应的权重、偏差、姓名以及储存的所有人脸特征。定义完这些后我们便可以开始写程序了。首先设置caffe的运行模式为cpu(当然你也可以选择gpu,但当时我的电脑显卡太烂,不支持CUDA):1
caffe.set_mode_cpu(); %设置运行模式
加载所需的模型:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15prototxt_dir =strcat(caffe_model_path,'/det1.prototxt'); %设置框架文件路径
model_dir = strcat(caffe_model_path,'/det1.caffemodel'); %设置模型数据路径
PNet=caffe.Net(prototxt_dir,model_dir,'test'); %加载模型
prototxt_dir = strcat(caffe_model_path,'/det2.prototxt');
model_dir = strcat(caffe_model_path,'/det2.caffemodel');
RNet=caffe.Net(prototxt_dir,model_dir,'test');
prototxt_dir = strcat(caffe_model_path,'/det3.prototxt');
model_dir = strcat(caffe_model_path,'/det3.caffemodel');
ONet=caffe.Net(prototxt_dir,model_dir,'test');
prototxt_dir = strcat(caffe_model_path,'/det4.prototxt');
model_dir = strcat(caffe_model_path,'/det4.caffemodel');
LNet=caffe.Net(prototxt_dir,model_dir,'test');
prototxt_dir = strcat(caffe_model_path,'/VGG_FACE_deploy.prototxt');
model_dir = strcat(caffe_model_path,'/VGG_FACE.caffemodel');
Net=caffe.Net(prototxt_dir,model_dir,'test');
其中caffe_model_path是放置模型文件的路径。模型加载完后需要读取图像并设置检测参数:1
2
3
4
5
6img = imread([PathName FileName]]); %读取图像
im_size = size(img(:,:,1)); %获取图像大小
minsize=floor(min(im_size)/10); %设置最小尺寸
expand_rate = 1.2; %设置扩展率
imshow(img) %显示图片
hold on %hold住啊
其中最小尺寸指的是MTCNN最小检测尺寸,我们设置为图像最小边的十分之一。它表示若图像中存在很小的人脸(尺寸小于整个图像的十分之一),那么我们便忽略它。而设置扩展率是由于MTCNN截的边界框往往比人脸略小,我们希望输入VGG-Net的图像是完整的人脸,因此需要将边界框扩展一些。接下来将图像输入MTCNN中得到人脸的边界框,并进行适当的调整:1
2
3[box, ~]=detect_face(img,minsize,PNet,RNet,ONet,LNet,threshold,false,factor); %检测人脸得到边界框
boudingboxes=scale_box(box,expand_rate,im_size); %调整边界框
numbox=size(boudingboxes,1); %边界框数目
其中detect_face函数是MTCNN官方定义的函数,它的输出是图像中人脸的边界框以及特征点。在这里我们不需要使用特征点,因此用~替代。scale_box 函数的作用是将变量box扩展并转换为可操作的数据结构。之后使用循环对每一个人脸进行裁剪,识别,并将它们的特征进行储存:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15featurelist = []; %创建特征列表
namelist = []; %创建人名列表
for i=1:numbox
rectangle('Position',boudingboxes(i,:),'Edgecolor','g','LineWidth',3); %在图像上显示边界框
face = cut_face(img,boudingboxes(i,:)); %裁剪人脸
face = prepare_image(face); %图像数据预处理
feature = Net.forward({face}); %输入到VGG-Face中得到人脸特征
[name,prob] = recognize_face(feature); %通过自定义softmax层检测人脸
if strcmp(name,'no data') %若人脸被检测为未在数据文件中,则设置为'???'
name = '???'
end
text(double(boudingboxes(i,1)),double(boudingboxes(i,2))+10,[num2str(i) '. ' name],'Color','r','FontSize',15); %将人名显示在图像中
featurelist = [featurelist feature{1,1}] %将人脸特征加入特征列表,至于为什么是feature{1,1}可以参照输出定义
namelist = [namelist {name}]; %将人名加入人名列表
end
这里要注意的是,由于在大家在训练模型的时候通常会对数据进行正规化(normalization),因此在使用模型时亦需要对输入数据进行相同处理,即预处理。这里使用的是prepare_image函数,其定义如下:1
2
3
4
5
6
7
8function img = prepare_image(img)
img = single(img);
averageImage = [129.1863,104.7624,93.5940]; %VGG-Face模型正规化参数
img = cat(3,img(:,:,1)-averageImage(1),img(:,:,2)-averageImage(2),img(:,:,3)-averageImage(3));
img = img(:, :, [3, 2, 1]); % convert from RGB to BGR
img = permute(img, [2, 1, 3]); % permute width and height
end
利用自定义softmax层识别人脸所使用的是recognize_face函数。其定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function [name,prob] = recognize_face(feature)
load([data_path '/face_data.mat']); %加载数据文件,data_path为文件所在路径
if isempty(face_data{1,3}) %若身份数据为空,则输出'no data'
name='no data';
prob=0;
else
output = fc_forward(feature{1,1},face_data); %输入softmax层得到输出概率
[prob,num]=max(output); %得到概率最大相应概率及身份
if prob < 0.6
name='no data'; %若概率低于识别阈值0.6,则name等于‘no data’
else
name=face_data{1,3}{num,1}; %否则name等于身份
end
end
end
以上便完成了输入图像并检测识别的过程。若需要修改身份并训练,则可以在交互界面修改,此时会更改namelist中相应的项。再使用新的身份列表和特征列表训练自定义softmax层。其实现代码如下:1
2
3
4
5
6
7
8
9n = size(namelist,2);
if n > 0
for i = 1 : n
if ~strcmp(namelist{1,i}, '???')
face_add(namelist{1,i},{featurelist(:,i)})
end
end
fc_train();
end
其中face_add函数将身份与对应特征加入数据文件中,其实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14function face_add(name,feature)
load([data_path '\face_data.mat']); %加载数据文件
[p,n]=ismember(name,face_data{1,3}); %判断身份是否在库内
if ~p(1,1) %若人名未在库内
face_data{1,1}=[face_data{1,1};(rand(1, 4096)-0.5)*2*sqrt(6 / 5000)]; %增加相应权重(weight)并初始化
face_data{1,2}=[face_data{1,2};0]; %增加相应偏差(bias)并初始化
face_data{1,3}=[face_data{1,3};{name}]; %增加相应身份
face_data{1,4}=[face_data{1,4};{feature{1,1}'}]; %增加相应特征
else %否则
face_data{1,4}{n,1}=[face_data{1,4}{n,1};feature{1,1}']; %增加相应身份的特征
end
save([data_path '\face_data.mat'],'face_data'); %保存数据文件
end
训练自定义softmax层用的是fc_train函数,其实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26function fc_train()
load([data_path '/face_data.mat']); %加载数据文件
iteration=800; %设置迭代次数
n=size(face_data{1,1},1); %得到身份总数
train_x=cell2mat(face_data{1,4}); %得到特征,设为训练数据输入
train_x=train_x';
train_y=[];
L=[];
for i=1:n %构造y的one-hot向量
temp_y=zeros(n,size(face_data{1,4}{i,1},1));
temp_y(i,:)=1;
train_y=[train_y temp_y];
end
for i=1:iteration
output=fc_forward(train_x,face_data); %前向传播得到输出
L=[L 1/2 * sum(sum((output-train_y) .^ 2)) / size((output-train_y), 2)]; %求出损失值
face_data=fc_backward(output,train_x,train_y,face_data); %反向传播更新权重
if mod(i,10) == 0
disp(['process:' num2str(i) '/' num2str(iteration)]); %输出训练进度
end
end
clf;
plot(L); %画出损失函数曲线
save([data_path '/face_data.mat'],'face_data'); %储存数据文件
end
更新数据文件其中前向传播与反向传播均自己定义,代码如下:1
2
3function output = fc_forward(train_x,face_data)
output = sigm(face_data{1,1}*train_x+repmat(face_data{1,2},1,size(train_x,2)));
end1
2
3
4
5
6
7
8
9
10function face_data=fc_backward(output,train_x,train_y,face_data)
l_rate=0.005; %设定学习率(learning rate)
reg=0.001; %设定正则化参数(regularization)
err=output-train_y; %输出与真实值偏差
doutput=err .* (output .* (1 - output)); %反向传播
dW=doutput * train_x' / size(doutput, 2) + reg*face_data{1,1};
db=mean(doutput, 2);
face_data{1,1} = face_data{1,1} - l_rate * dW; %更新权重
face_data{1,2} = face_data{1,2} - l_rate * db; %更新偏差
end
更新数据文件后我们便能用新的权重来识别了。
测试
整个交互界面如下图所示:![]()
Open Image按钮选择并显示图像;Recognize按钮识别并将识别的身份显示在右侧列表内;Change按钮更改列表中人名;Save按钮训练并保存数据文件;DataClear按钮清除数据文件。测试时我们先清楚数据文件,之后使用一张图片作为训练数据对网络最后一层进行训练。训练图片如下:![]()
训练完毕后使用另一张测试图片识别:![]()
使用摄像头识别:
![]()
![]()
效果还不错啦。
不足与改进
可以说这是我深度学习第一个应用的项目,当时并不知道迁移学习的概念,只是单纯发现自己电脑跑不动深度网络,无奈之下采取了这种方式。整个项目还是有很多不足的地方,比如之前在设计识别阈值时候纠结了半天,并且效果还不好。而其实softmax的输出并不能完全当作概率来看,每次增加新身份后它的输出值都会相应下降。正确的做法是在已有身份之外再设置一个”unknown”身份,若输出向量中”unknown”数值最大则视为人脸未识别。
另外就是交互功能不完善,纯粹是为了交互而交互。不过当初设计也就是为了好玩,是肯定不能应用到实际中的。
小结
- 迁移学习是将已经训练好的网络迁移到新任务中使用的方法,可以大大提高开发效率。
- 迁移学习需要新旧任务有关联性。
- 迁移学习应用举例。